In this blog post, we will discuss how we can "cache" entries from the database. We will talk about why we would do this in the first place and how to achieve that.
Also, we will talk about some implications and what "cache invalidation" is.
What is caching, and why do we do it?
Let's start from the beginning. Why do we cache things? The easy answer is to boost the performance of our application. Caching means we store the data in memory for faster access. For example, if we have a database where we normally have a roundtrip over the wire to access the data, we just look in our RAM to retrieve the object. The overall goal is to increase performance and scalability.
There are many big projects like redis that are famous for caching, but often times that can be an overblown solution for simple cases. So we will shed some light on IMemoryCache, a simple caching solution for .NET.
If you are using ASP.NET Core you already have IMemoryCache available. In any other case, you can install the package via:
dotnet add package Microsoft.Extensions.Caching.Memory
And add the dependency via:
services.AddMemoryCache();
Now you are good to go. Again, for ASP.NET Core you do not have to do those steps. The general flow would look like this: We ask the cache for an entry, and if it is present we return it. If not, we retrieve the entry from the "real" storage provider (like a database or Web API call) and then save it in our cache. The next time we ask the cache for an entry, we can directly return it from the cache without going to the underlying provider again:
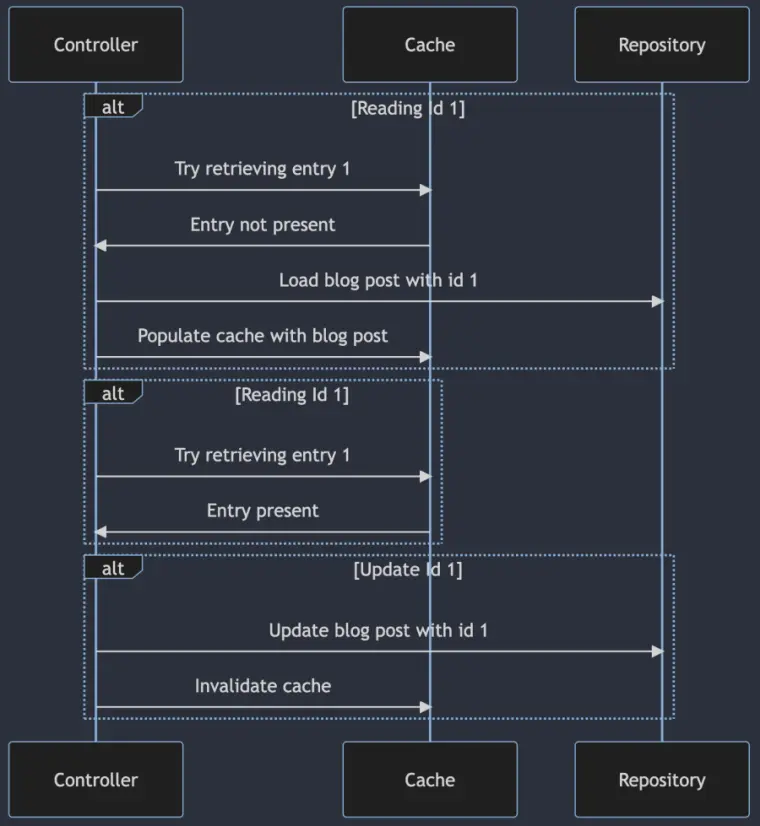
The memory cache is basically a Dictionary<TKey, TValue>. So we define a key, like a string that maps uniquely to a value inside that cache. Now of course it is a bit more complex, but for now let's assume it is a very nice Dictionary. So one task we have to do is find a unique key for our entries. I will show an example where we retrieve blog posts by key from a data base. The id makes a perfect key!
Usage
The easy part: Adding the interface as constructor dependency:
public class BlogController : Controller
{
private readonly IBlogRepository _blogRepository;
private readonly IMemoryCache _memoryCache;
public BlogController(IBlogRepository blogRepository, IMemoryCache memoryCache)
{
_blogRepository = blogRepository;
_memoryCache = memoryCache;
}
}
Know how would it look like if we have a route that retrieves a blog post for a given id?
public async Task<IActionResult> GetBlogPost(int id)
{
// Cache key
var cacheKey = $"BlogPost_{id}";
// Check if the cache contains the blog post
if (!_memoryCache.TryGetValue(cacheKey, out BlogPost blogPost))
{
// Retrieve the blog post from the repository
blogPost = await _blogRepository.GetBlogPostByIdAsync(id);
// Save the blog post in the cache
_memoryCache.Set(cacheKey, blogPost);
}
return Ok(blogPost);
}
Perfect! That was almost all! The code is exactly as in the sequence diagram above. We create the key as string that has the word blogpost and the given id. Remember that there is only one IMemoryCache instance over your whole application, so a unique key is crucial! Now one important thing here to mention is that with the current setup, the cache entry is valid indefinitely! That can lead to stale data! We take care of that later.
Deleting a cache entry
But what happens if we need to invalidate an entry? For example, if we update the blog post, we also want to clear the entry of the cache so that users also get the latest and greatest state.
[HttpPost]
public async Task<IActionResult> UpdateBlogPost(BlogPost updatedBlogPost)
{
// Update the blog post in the repository
await _blogRepository.UpdateBlogPostAsync(updatedBlogPost);
// Clear the cache entry for the updated blog post
_memoryCache.Remove($"BlogPost_{updatedBlogPost.Id}");
// Redirect to the updated blog post's page
return Ok();
}
Expiration window
I said earlier that the cache is valid indefinitely. That is not necessarily good. It can pile up memory over time even though entries are not used anymore. To overcome that the IMemoryCache offers us an overload where we can pass in some additional options.
// Retrieve the blog post from the repository
blogPost = await _blogRepository.GetBlogPostByIdAsync(id);
// Cache entry options
var cacheEntryOptions = new MemoryCacheEntryOptions()
.SetSlidingExpiration(TimeSpan.FromMinutes(5));
// Save the blog post in the cache
_memoryCache.Set(cacheKey, blogPost, cacheEntryOptions);
We can pass is MemoryCacheEntryOptions. We see also a method called SetSlidingExpiration where we can tell how long the cache entry is valid. Next to sliding expiration, we have absolute Expiration (via SetAbsoluteExpiration). What is the difference between those two?
Sliding Expiration Window:
In a sliding expiration window, the cache item expires after a specified duration of inactivity. Whenever the item is accessed, the expiration timer is reset. This approach is beneficial for items that are frequently accessed, as they remain in the cache longer, improving performance. However, less frequently accessed items are removed from the cache, freeing up memory for other, more relevant data.
Absolute Expiration Window:
With an absolute expiration window, the cache item expires at a fixed point in time, regardless of whether it's accessed or not. This approach ensures that data doesn't remain in the cache longer than the specified duration, which is useful when dealing with data that changes periodically or has a known update schedule. It helps maintain data accuracy by ensuring that stale data is evicted and replaced with fresh data when required.
Evicting all data
There is also an option to invalidate the whole or parts of the cache at once. For that, we can utilize a CancellationToken. If we call Cancel all entries that are linked to that token are invalidated.
public class BlogController : Controller
{
private readonly IBlogRepository _blogRepository;
private readonly IMemoryCache _memoryCache;
private CancellationToken resetToken = new();
And add the token to the entry:
public async Task<IActionResult> GetBlogPost(int id)
{
// Cache key
var cacheKey = $"BlogPost_{id}";
// Check if the cache contains the blog post
if (!_memoryCache.TryGetValue(cacheKey, out BlogPost blogPost))
{
// Retrieve the blog post from the repository
blogPost = await _blogRepository.GetBlogPostByIdAsync(id);
var cacheEntryOptions = new MemoryCacheEntryOptions().AddExpirationToken(new CancellationChangeToken(resetToken));
// Save the blog post in the cache
_memoryCache.Set(cacheKey, blogPost, cacheEntryOptions);
}
return Ok(blogPost);
}
Now a call on resetToken.Cancel will cancel all of our entries associated with said token. That brings us to the hard part of caching: Cache invalidation.
Cache invalidation
Cache invalidation is the process of removing or updating stale data from the cache, ensuring that the application works with accurate and up-to-date information. The complexity of cache invalidation arises from the need to maintain a balance between data consistency and performance improvements.
The famous quote by Phil Karlton, "There are only two hard things in Computer Science: cache invalidation and naming things,"* highlights the challenges associated with cache invalidation. The main issues with caching and cache invalidation are:
- Data Consistency: When data is updated in the primary data source, it's crucial to ensure that the cached data is updated or removed to maintain data consistency. Failing to do so may cause the application to use stale data, leading to inaccurate results or unexpected behavior.
- Cache Invalidation Strategies: Choosing the right cache invalidation strategy is vital, as different applications have different requirements. The strategies include time-based expiration (absolute or sliding), event-based expiration, or manual invalidation. Selecting an appropriate strategy can be challenging, as it requires a thorough understanding of the application's data access patterns and update frequency.
- Cache Thrashing: When cached data is frequently invalidated, it can lead to cache thrashing, where the cache is continuously filled with new data and then invalidated, reducing the benefits of caching. Identifying and resolving cache thrashing scenarios is essential for optimal performance.
So striking a balance between all those factors can be challenging and can bring great complexity to your code. That said, you have to check in your context and setup if caching is worth the effort.
Let's say you have a blog like you are reading right now. 99% of access to this website is read-only. I do use said caching in my blog. It is easy to oversee the scenarios where I have to update the cache (basically when updating a blog post). It looks more difficult the more write scenarios you have!
Conclusion
Caching is a powerful technique for enhancing application performance by reducing the time and resources required to access frequently requested data. However, the challenges associated with cache invalidation, such as data consistency and choosing the right strategy, must be addressed to reap the full benefits of caching. By understanding the application's data access patterns and carefully designing the caching strategy, developers can strike a balance between performance improvements and data accuracy, resulting in a more efficient and responsive application.


