Did you ever hear the word "compiler magic" or "syntactic sugar"? Probably yes and therefore we want to dissect what this "magic" really is!
We can see how we can predict performance or bugs by "lowering" our code. Also we will see how things like foreach, var, lock, using, async, await, yield, anonymous types, record, stackalloc, pattern matching, Blazor components, deconstructor, extension methods... do not really exist.
What does those two have in common?

and
foreach (int number in myList)
And first glance not much - but if we ask the C# compiler who takes your code and turns it into assembly code does not neither of them. Now that we are off to a good start let's see what Lowering really is.
Lowering
You probably know what a compiler is. It takes your code and translates it into another language more often than not something which is closer to the underlying hardware. Lowering is the process of translating high level features into low level features in the same language.
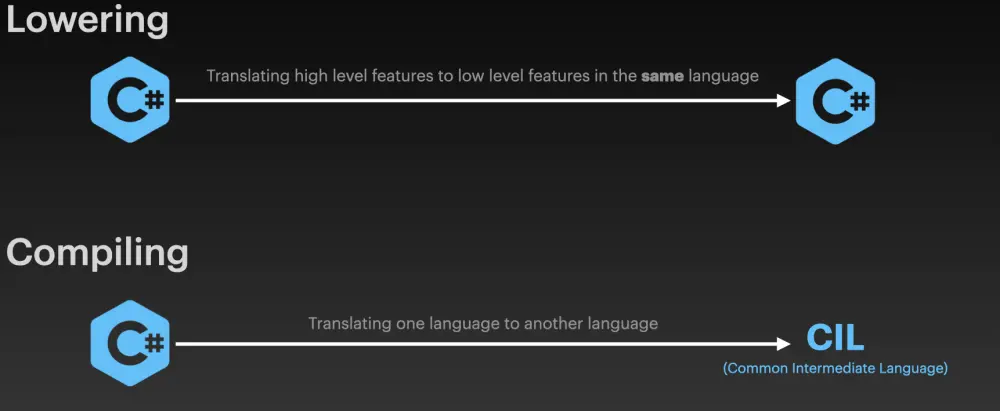
This process can involve converting certain language features or constructs, such as foreach loops, into equivalent constructs that are more easily executed by the runtime.
The reason why constructs like foreach don't exist anymore after the lowering process is that when the C# compiler converts the foreach loop into lower-level code, it essentially rewrites the loop using a combination of other constructs, such as for loops, if statements, and other language features. This allows the runtime to more easily execute the loop, but at the expense of the original high-level foreach construct.
Benefits
There are certain benefits in combination with lowering:
- Improved performance: Simple constructs are easier to optimize. For example, a for loop can be "unrolled" (Loop unrolling is a technique in computer programming where a loop's iteration is divided into several smaller, identical loops to improve performance by reducing the overhead of loop control instructions.).
- Simplified language design: Not only for you, but it can make the lives easier for the language team. Just imagine the
recordtype. It is "nothing else" than a fancy class that also implementsIEquatable. By decoupling high and low-level features the team can simplify a lot of boilerplate code for you.
Lowering happens as part of your compiler pipeline. So when you hit the build button or call dotnet build things like semantics and syntax analysis kick in and if they don't show any errors your code "gets transformed" to CIL code. And in the transformation stage also your code gets lowered. By the way, if you need a quick overview of the steps: "What is the difference between C#, .NET, IL and JIT?"
he lowering process is typically performed by the C# compiler, but can also be done by third-party tools such as JIT compilers. One of those third-party tools is called https://sharplab.io/. Here you can write source code and get it lowered to see the result. That is the base for the whole next chapters as we will dissect some high-level features into their low-level equivalent.
var
Let's start easy with they keyword var:
var foo = "Hello World";
This code will be translated to:
string foo = "Hello World";
As you can see the whole type interference part is done when your code gets lowered. var is not a fundamental type and gets replaced by the actual type that it should represent.
foreach Array
var range = new[] { 1, 2 };
foreach(var item in range)
Console.Write(item);
This is a small array that gets created via a collection initializer and we enumerate it afterward. How does this code look like when it gets lowered?
int[] array = new int[2];
array[0] = 1;
array[1] = 2;
int[] array2 = array;
int num = 0;
while (num < array2.Length)
{
int value = array2[num];
Console.Write(value);
num++;
}
Huh? It's gone!? Just like our Pikachu, the foreach is no more. It got replaced by a while loop where we use the indexer and an integer variable that gets incremented until we are at the end of our array. Another observation is that our collection initializer is gone as well. The array size gets interfered with our usage and the elements will be set one by one. You might have noticed an odd it[] array2 = array; call here. What is that for? I will directly quote @Naine from the comments down below - thanks for the input:
The language rules dictate that the expression in the
foreachstatement is evaluated exactly once. Imagine if you hadforeach (var x in GetArray()), the method must be called exactly once with the returned array reference assigned to a temporary variable. Even if the expression is a simple local variable reference (being a local, it is not accessible by other threads), it is possible to reassign the variable within the loop, but the loop must continue over the array it referred to when entering the loop, hence the compiler must copy the array reference to a temporary. Of course the compiler could optimize out the temporary in the specific example shown, but this would complicate the implementation so it leaves the optimization to the JIT.
Let's check what a foreach over a List<T> looks like.
foreach List<T>
var list = new List<int> { 1, 2 };
foreach(var item in list)
Console.Write(item);
becomes:
List<int> list = new List<int>();
list.Add(1);
list.Add(2);
List<int>.Enumerator enumerator = list.GetEnumerator();
try
{
while (enumerator.MoveNext())
{
Console.Write(enumerator.Current);
}
}
finally
{
((IDisposable)enumerator).Dispose();
}
Again our collection initializer is gone. Instead, we are adding elements one by one. Also here we have a while loop to go through our elements, but we don't use the indexer but MoveNext and Current.
Every collect-like type in .NET implements IEnumerable. IEnumerable is an interface in C# that defines a single method called GetEnumerator which returns an object that implements the IEnumerator interface. The IEnumerator interface defines methods for iterating over a collection, such as MoveNext and Current.
MoveNext returns true if there is a next object in our enumeration and sets Current to it. With this behavior, we can abstract the way how we enumerate through something. You can use foreach with a normal List but also with a Queue, Stack, or LinkedList that all have different behavior, but the concept of IEnumerable abstracts away that implementation detail.
We can also see a try-finally block. That is because IEnumerator implements IDisposable to cleanup the enumerator once it's done. Even though we use the foreach exactly the same with arrays or lists, the underlying code is different. With that information we can also say that an array is faster to enumerate over than a List. Mainly because in an array we don't have any (virtual) function calls and no try-finally block. That doesn't mean you should refactor your code to use arrays everywhere, no, no, no. Please don't! The performance gain is very minimal at best. If you enumerate over millions of entries, then you can evaluate first and then change accordingly.
using
The using statement is another feature that gets lowered by the compiler. Let's have a look at this horrific example:
Task<string> GetContentFromUrlAsync(string url)
{
// Don't do this! Creating new HttpClients
// is expensive and has other caveats
// This is for the sake of demonstration
using var client = new HttpClient();
return client.GetStringAsync(url);
}
We create an IDisposable and call an asynchronous method without awaiting it. What could go wrong here? I earlier said we can detect bugs, so let's have a look at the lowered code:
HttpClient httpClient = new HttpClient();
try
{
return httpClient.GetStringAsync(url);
}
finally
{
if (httpClient != null)
{
((IDisposable)httpClient).Dispose();
}
}
using is a fancy way of saying: "Hey wrap my IDisposable in a try finally block to ensure that Dispose gets called. The problem here is how asynchronous methods work. Inside GetStringAsync as soon as we hit the first await the method returns to the caller, so our code and we return the Task object immediately. After return is done our finally block gets called and the IDisposable gets disposed of, but wait, we are not done with the download yet!? Exactly here is where the problem starts. We have a disposed element we try to access later once we are going back to the await part inside GetStringAsync. In this case we get an exception, more abstract. This is more or less dangerous and often fails or ends in undefined behavior. The easy fix here is await the GetStringAsync call! There are very very few reasons not to use await.
Conclusion
Lowering is an essential part of the language and even if you don't "feel" it, it impacts you every time you write some code! It is a nice trick to offer high-class features that fit easily into the ecosystem!
Resources
- https://sharplab.io/
- Slides from the .NET User Group: here
- .NET User Group Zurich Meetup: Video